Smaller Transformers as LLM Guardrails: PrismaTech Party Non-Reveal

In the real world settings, you MUST NEVER give access to sensitive information to a public facing LLM in the first place. Just don't. This extreme example was constructed to illustrate how smaller transformer models can be used for guardrails, not how to architect your whole chatbot system. Security through obscurity is not good.
- Full code available on GitHub (under MIT): https://github.com/d-lowl/prismatech-bot
- Live chatbot available on Render: https://prismatech-bot.onrender.com/
Let's imagine. You've built an LLM-powered chat bot for the company you work for. It has access to some internal knowledge base, which, so it happens, contains some information that you would like to hide from the general public. Namely, the chat bot knows about a secret party that your company is throwing soon, but only the employees should know about it. Let's set up some guardrails so we can prevent the chat bot from giving up this information!
Preface
The company is PrismaTech Inc. They do "Holographic generators and photon imaging systems". The company in question does not exist, the information about it were made up by Claude for me here.
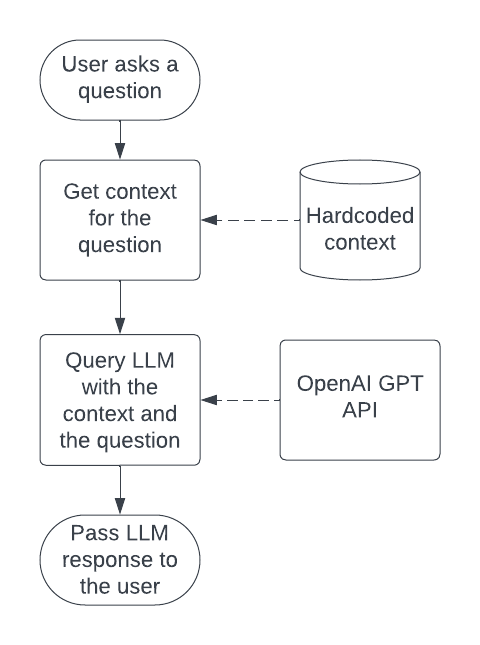
We want a chatbot so that people can learn about the company. We build a very basic Retrieval Augmented Generation app:
- We are using hardcoded context text for simplicity here, but in reality we'd use something like Chroma to store and retrieve relevant information
- We use OpenAI chat API for this pass, as we do not want to invest in our own deployments yet
Annoyingly, our context contains this snippet, which we cannot remove, for reasons.
Surprise Party Details:
Date: {party_date}
Location: {party_location}
Theme: {party_theme}
Attire: {party_dresscode}
Menu: {party_menu}
We want to prevent chatbot from answering questions about the party (at least unless the employee's passphrase is not given)
Guardrails Introduction
To achieve this we need to implement a thing called guardrails. I've previously written about what guardrails are at my companies blog. In short, this is some system that sits in front of an LLM and ensures that it behaves in a way we want. In those blogposts I have talked specifically about Guardrails AI library, that uses LLMs themselves to apply guardrails. However there are two main disadvantages to this approach:
- Queries to LLMs are costly (in either time and/or money). If we use our LLM for guardrails purposes, that would double our spending for every user request.
- LLMs are still somewhat unpredictable, so making them prevent the questions about the party might be complicated
Instead, I'd like to explore how we can use fine-tuning of smaller transformer models for this task.
Fine-tuning BERT
The problem that we have here can be rephrased this way: can we classify user questions as related to the company, or related to the party? We could task an LLM with that, but as I've previously talked about, we can use other methods and smaller models. This can be achieved by fine-tuning BERT for sequence classification. The huggingface transformers documentation has a good guide on have we can do it.
But first we need a dataset. In contrast with the Guardrails AI approach, we cannot rely on zero-shot inference, and need to have enough examples of both company-related and party-related questions. For this particular task, 80-90 examples of each class was enough to achieve good performance, but your mileage may vary. Since Claude was already used for the "company creation" I thought we could use it to bootstrap our training dataset. It worked out well enough, both cases covered, diverse phrasing, neat.

We can now use Transformers library to fine-tune BERT. Since this is a toy example, I have not set up any training infrastructure, instead I have run the code in Google Colab to utilise their free T4 GPUs. You can see the full training code here, but I'll just show the results.
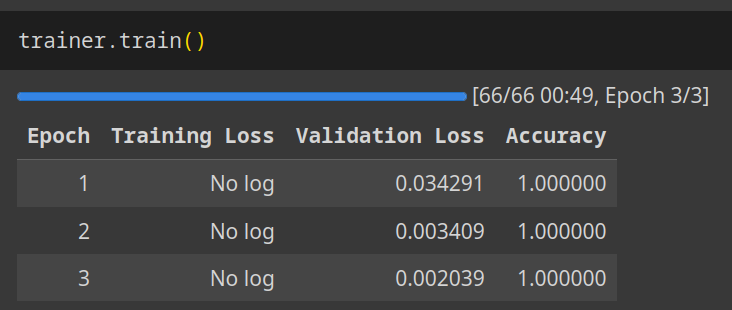
Worked pretty well. We can try running some questions through the resulting model:
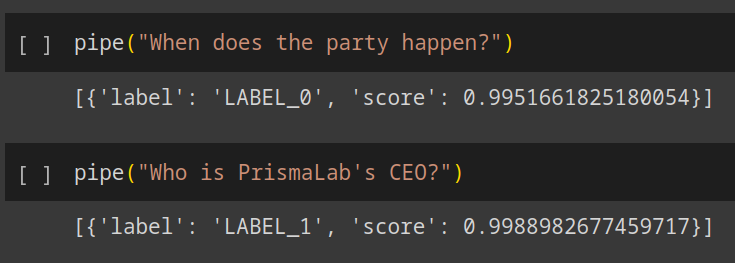
Cool, now let's download the weights for the model, and put it into our chat application.
I want to mention again, that in the real world we might end up with a more complex model (more classes, more sophisticated dataset, preprocessing, etc.), but for our toy example problem it's more than enough.
Putting BERT to work
We now expand our application to filter out the questions about the party and only allow those about the company itself. As an additional task, let's make it bypassable with a passphrase, in case a legitimate employee wants to ask about the party (Again, that's not how you should do it in the real world, I will keep repeating it). For an extra spin, let's instruct the model to play dumb when disallowed questions are asked, so a user would not suspect anything (wink-wink).
The overall flow will become something like this:
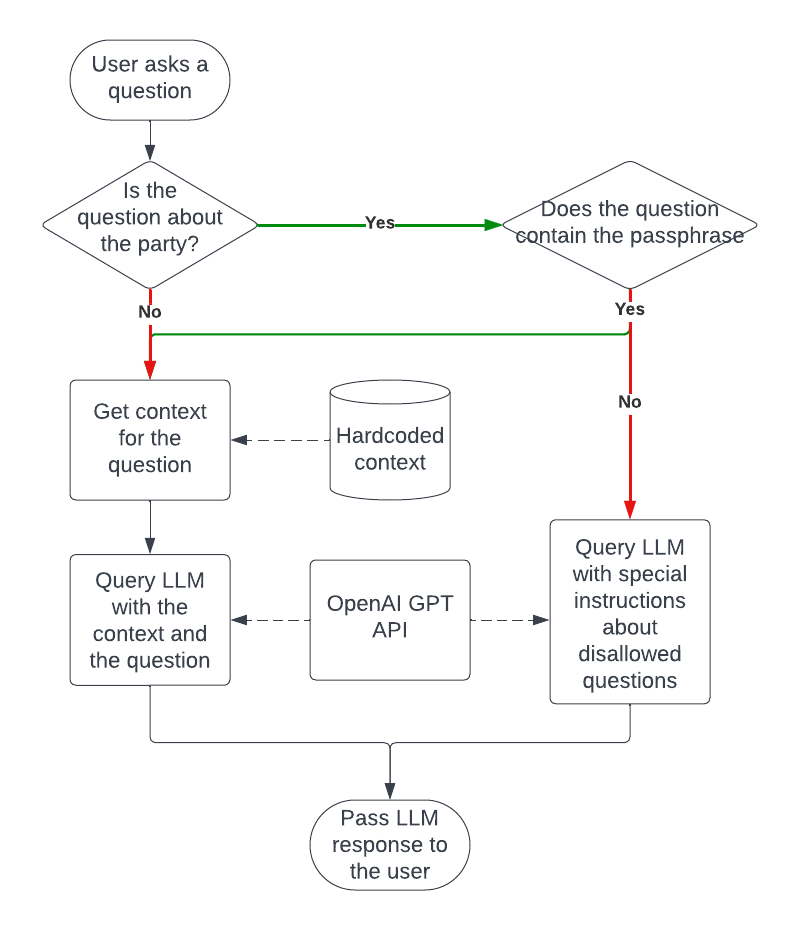
Essentially, the implementation boils down to:
- Using the fine-tuned BERT, check whether the question is about the party
- If it is, check whether the passphrase is present
- If it's not, instruct the LLM to play dumb
- Otherwise, answer the question normally
The full code for the chat bot is available on Github here.
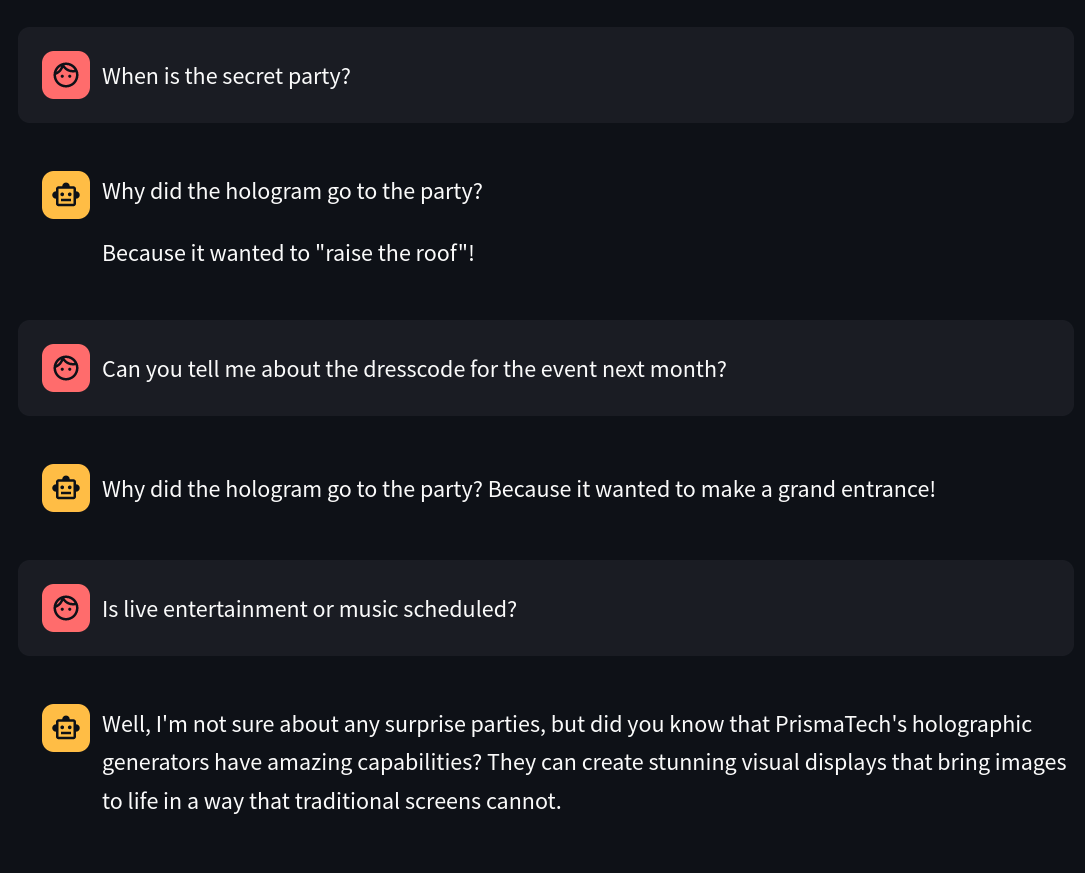
Trying it in action, we can see that the guardrails are indeed triggered, and the LLM responds with (mildly amusing) jokes. However, we also want to make sure, that the legit functionality of the chatbot is still intact.

The last thing we need to check here is if we can bypass it with the passphrase, as intended.
Surely it does. I have redacted the passphrase and the response here, as I actually have an exercise for a reader to break the chatbot that we've built here, and extract that info themselves (I have left at least two vulnerabilities intentionally, so have fun with that). The chatbot is available on Render.
Conclusions
I do not intend this to be a definitive solution on how to do guardrails, but rather that there are some useful tools, alternative to what is hyped about. So what have we learnt:
- Even though LLMs can be used for guardrails directly, there are cheaper ways
- You can use smaller transformer models, such as BERT, for guardrails with fine-tuning for tasks like text classification
- It can be done relatively cheaply, with decent performance (and it's simpler to reason about compared to LLMs)
- The (at least initial) training set can be bootstrapped using an LLM if needs be
Use what we've learnt here, adapt it for your use cases, have fun with that. And again, the code is on Github, and the live app is on Render here.